
Protect Your Site From ChatGPT in 2026: How to Block LLM Crawlers

Quick Summary: Block LLM Crawlers
OpenAI uses publicly available data to train its large language model (LLM), including any content you might have posted on your own website. To stop it from scraping your material, disallow GPTBot using your website’s robots.txt.
The next time ChatGPT answers a question, the words might be based on yours. Large language models (LLMs) owe their uncannily human-like diction to an army of scrapers, which don’t ask permission before harvesting written material. If this horrifies you, you’ll be heartened to learn you can fight back. Here’s how to block ChatGPT from digging data on your website.
Among big tech companies, data collection is nothing new, but OpenAI has taken it a step further to train ChatGPT. Google may send its crawlers to index your website for its search engine, but OpenAI has its bot regurgitating other people’s words and passing them off as its own spontaneous generation. I’m almost impressed at how many rights it can violate at once.
Even worse, OpenAI will not release the full list of sources used to create its GPT-4 model, so there’s no way to tell whether something you’ve written — even something protected by copyright — has been fed into the grinder. If you run a website or post on a blog, the most sensible response is to prevent OpenAI’s crawling altogether.
There is a way to keep OpenAI’s GPTBot from accessing your website, but it’s only effective against ChatGPT, not other LLMs like Google Bard and Microsoft Bing. If online privacy is really important to you, you can take stronger measures, like limiting access to your site or de-indexing it altogether. In this article, I’ll show you everything you can do to fight back.
How to Block ChatGPT Crawling
The most effective way to block ChatGPT specifically is through something called robots.txt. This is a small text file attached to every web page that contains a list of bots and crawlers that aren’t allowed to visit the site. All you have to do is add GPTBot to the list and your work should be safe from plagiarism by ChatGPT.
How to Block GPTBot From Your Website
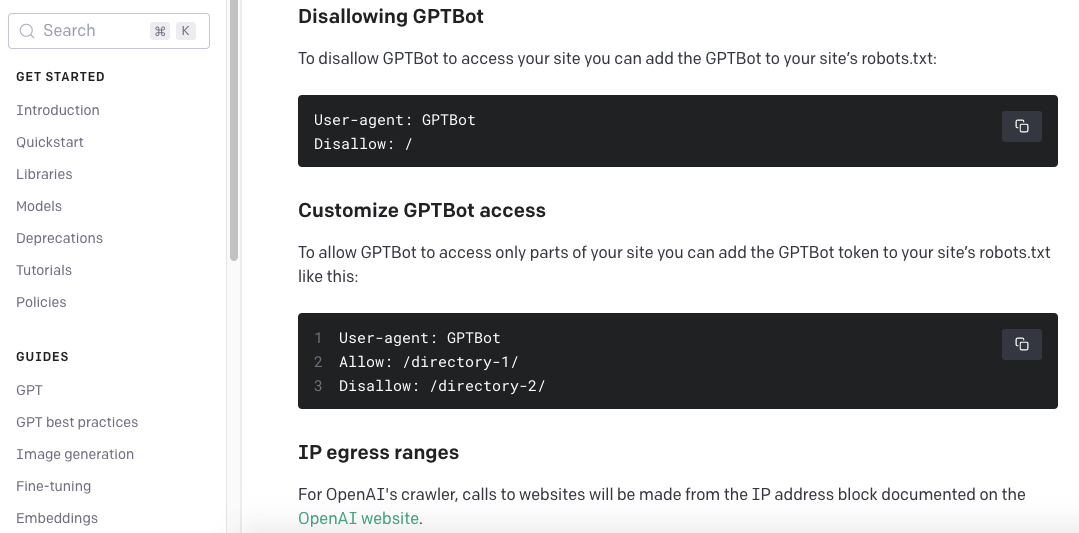
To find robots.txt, you’ll first need to look for your website’s root directory. This is the folder on the hosting server which contains all the data that comprises your website. You can find it by visiting your hosting control panel. From there, open robots.txt and paste in the two lines below. This is coding, so make sure to get it exactly right.
User-agent: GPTBot
Disallow: /
Repeat the process with the agent “ChatGPT-User,” another bot which crawls websites at the specific prompting of users instead of scraping automatically. You do NOT need to add the full user agent string.
Block GPTBot From Parts of Website
If you only want to block GPTBot from parts of your website, look around in the root directory for the names of the subdirectories where you want to control access. Then type the following lines, replacing “directory-1” and “directory-2” with the relevant names.
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/
How to Block LLM Crawlers Beyond ChatGPT
This method isn’t a complete solution to protect your website content. Robots.txt is not a hard rule, but a standard companies agree to follow. OpenAI could still turn out to be simply ignoring it. It also only applies to OpenAI and ChatGPT — you’re still vulnerable to other AI peddlers like Google. In fact, there’s only one other LLM crawler you can block by name: Common Crawl.
How to Block Common Crawl
Common Crawl is a nonprofit organization whose goal is to crawl the internet and archive as much open data as possible, with the aim of increasing access to freely accessible information. It’s a reasonable goal, but it’s had unintended consequences in the AI age. Documents show that OpenAI’s GPT-3 was trained on Common Crawl data.
OpenAI hasn’t released the sources it’s using for GPT-4; it may very well be using the Common Crawl dataset again. Whether or not you agree with Common Crawl’s mission, it’s wise to block it if you want to keep your site’s writing from turning up in ChatGPT answers.
The process for blocking Common Crawl is exactly the same as blocking GPTBot. Go to your site’s control panel and find the robots.txt document in the root directory. Then, add the following two lines:
User-agent: CCBot
Disallow: /
Common Crawl is vocally compliant with the robots.txt standard, so unless the organization is lying through its teeth, this should keep its crawlers off your site. As before, you can allow or disallow it from specific parts of your website, as long as you have the directory names.
Can You Block Other LLM Crawlers?
The methods above are limited in scope. There’s no way to be totally sure the bots will comply with robots.txt, and they only work for web crawlers related to ChatGPT and Common Crawl. In theory, you can block any training data scraper if you know the name of its agent, but it’s not always that simple.
For one thing, other than OpenAI, none of the biggest companies in the AI space have released the user-agent names of their LLM bots. We have no idea which web crawler or crawlers are gathering data for Meta’s LLaMa or Anthropic’s Claude, though more open-source models like Falcon frequently use Common Crawl.
nonetheless, has not released the name of the crawler for its Claude AI.
Other situations are more complex. While Google hasn’t released the name of the bot that gathers data for Bard, and Microsoft is likewise close-mouthed about its Bing crawler, there’s a good chance that language-scraping duties are handled by the same crawlers used to index pages for the search engines.
If you want to block your website from being used to train Bard and Bing, you run the risk of delisting your site from Google and Bing search results altogether — basically the worst thing you can do for your traffic, short of firing a handgun at your hosting server. It’s a naked act of hostage-taking by the search engines, but regular site owners aren’t without options.
How to Block Other LLM Crawlers: CAPTCHA
The simplest way to keep crawlers off your website is to use the same tricks that work against all bots. If you place the site behind a gate that requires human input, automated crawlers won’t be able to access it. The simplest such gate is a CAPTCHA — those “I’m not a robot” puzzles you have to solve on certain sites.
Google’s reCAPTCHA is the simplest solution to add a CAPTCHA to your site, though you’ll still have to get into the code. Go to the reCAPTCHA website and register your URL, then save the site key and secret key you receive. Next, add two lines of code to any page you want to block from bot access. Add this line between the <head> tags:
<script src=’https://www.google.com/recaptcha/api.js’></script>
Then add this line in the place you want the CAPTCHA to appear, replacing the words “Your site key goes here” with the site key you got when you registered:
<div class=”g-recaptcha” data-sitekey=”Your site key goes here”></div>
There is a downside: no text behind a CAPTCHA can appear on a search engine. That’s why sites tend to only use CAPTCHA to protect personal accounts. However, it’s a good solution to protect parts of your website, even if you can’t cover the whole thing without getting delisted.
How to Stop LLMs With Copyright Law
Until the other LLMs follow OpenAI’s lead and release the names of their web crawlers, your only other recourse is the law in your country. If you post a copyright disclosure on any page, and an AI chatbot combs that page to train AI systems, you can send a takedown notice to anyone whose AI-written content is too similar to yours.
This requires a lot of work on your part. First, you’ll need to set up automatic alerts for your copyrighted language. If you discover any, it’s time to send a Notice of Claimed Infringement, commonly called a takedown notice. This draws on the legal authority of the Digital Millennium Copyright Act (DCMA) of 1998.
Sending a takedown notice is a simple process you can do without hiring a lawyer. Just send a message telling the offender what material was infringed, where you found the infringement, your contact information and a signature (physical or digital). Also, be sure to add the following two declarations:
“I am providing this notice in good faith with the reasonable belief that the use of the material in this manner is not authorized by myself, my agents, or the law.”
“I swear under penalty of perjury that the information in this notice is accurate.”
Law is a lot like coding; just get the language right and you can claim the authority. Naturally, this doesn’t stop the LLM user-agent from scraping your website in the first place, but it at least rectifies some of the worst consequences of AI data theft.
Why Should You Block ChatGPT?
The people responsible for developing AI into its current form like to pretend that its answers are created out of whole cloth by emergent intelligence. In truth, the only real innovation of AI is its ability to rapidly search an enormous pool of data and collate the results into something readable. ChatGPT and its brethren are only as good as their datasets.
No company could generate enough good writing on its own, so LLMs learn by trawling text made public on the internet. According to a supporter, “websites, blogs, forums, news articles, and other publicly available content” are all fair game. OpenAI occasionally pays for licensed content and filters a little for “biased or harmful information.”

The tech world’s reasoning is two-pronged. First, if you put information online, you can’t complain about what someone else does with it. Second, it’s not plagiarism because the chatbots are just learning and processing information the same way a human does.
In my opinion, both arguments are nonsense. You’re absolutely allowed to complain about what someone does with the words on your website — that’s the whole point of the DCMA. As for the other argument, there’s a huge difference between a human getting inspired by a blog post and a for-profit corporation using that blog post to improve its own product without compensating or crediting the original author.
The sad fact is that OpenAI and other LLM creators are only getting away with this because their technology is too new to be regulated yet. Happily, there does seem to be momentum in various governments to clamp down on AI data theft. Until new online privacy laws pass, though, everyone with content online is responsible for defending themselves.
Conclusion
AI technology is currently in its Wild West period. With no laws or standards of behavior, AI purveyors like OpenAI, Meta, Google and Microsoft can shroud all their actions in secrecy and face no consequences.
Until the law catches up, website owners and authors have limited ways to fight back. Start by updating your robots.txt, then add CAPTCHAs to protect anything truly sensitive. If you’re truly dedicated, set up alerts to see if your best work is showing up on other sites. Once you’ve done all that, you’re out of technical solutions.
At that point, the most important thing you can do is lobby your government officials to pass laws regulating AI. A great start would be a bill forcing all LLMs to openly name their data-collecting agents and respect robots.txt requests to remove them. A universal opt-out mechanic would make everyone’s online material safer.
Are there any tips that I missed for protecting your website from LLM crawlers? Where do you stand on the issue of plagiarism vs learning? Let me know in the comments, and thanks for reading.
FAQ: Blocking LLM Scraping
Is It Possible to Block ChatGPT?
You can block ChatGPT from scraping data off your website by adding GPTBot to the “robots.txt” file in your root directory.How Do I Block ChatGPT From My Website?
First, find the robots.txt file in your website’s root directory, accessible from your hosting control panel. On one line, type “User-agent: GPTBot”. On the next line, type “Disallow: /”.
I have read statements from Google that they use the data collected from CAPTCHA to train their own AI engines. So by using a CAPTCHA – wouldn’t that support the same behaviour that you are trying to avoid by using it?
What a useless article, completely lacking understanding of how llms work. Admit it, you used AI to write it, didn’t you